Zhipu AI/Mixture of Experts
GLM 4.6
chatcodingreasoningtool_useThinkingTool Use
357B
Parameters (12B active)
195K
Context length
7
Benchmarks
4
Quantizations
47K
HF downloads
Architecture
MoE
Released
2025-08-08
Layers
92
KV Heads
8
Head Dim
128
Family
glm
Model Card
View on HuggingFaceGLM-4.6
<div align="center"> <img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/> </div> <p align="center"> 👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community. <br> 📖 Check out the GLM-4.6 <a href="https://z.ai/blog/glm-4.6" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report(GLM-4.5)</a>, and <a href="https://zhipu-ai.feishu.cn/wiki/Gv3swM0Yci7w7Zke9E0crhU7n7D" target="_blank">Zhipu AI technical documentation</a>. <br> 📍 Use GLM-4.6 API services on <a href="https://docs.z.ai/guides/llm/glm-4.6">Z.ai API Platform. </a> <br> 👉 One click to <a href="https://chat.z.ai">GLM-4.6</a>. </p>Model Introduction
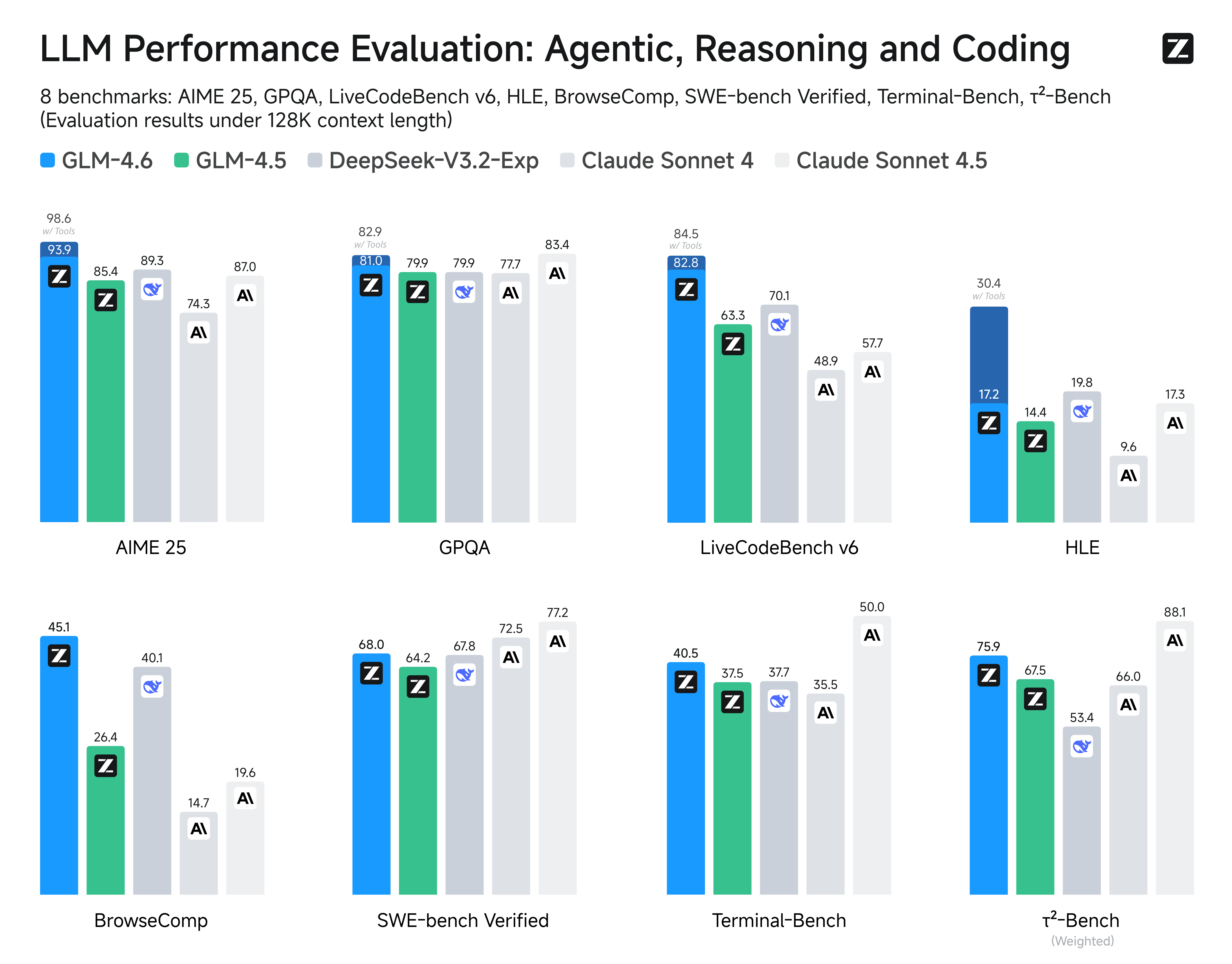
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
- Longer context window: The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
- Superior coding performance: The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
- Advanced reasoning: GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
- More capable agents: GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
- Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
Inference
Both GLM-4.5 and GLM-4.6 use the same inference method.
you can check our github for more detail.
Recommended Evaluation Parameters
For general evaluations, we recommend using a sampling temperature of 1.0.
For code-related evaluation tasks (such as LCB), it is further recommended to set:
top_p = 0.95top_k = 40
Evaluation
Quantizations & VRAM
Q4_K_M4.5 bpw
202.1 GB
VRAM required
94%
Quality
Q6_K6.5 bpw
291.1 GB
VRAM required
97%
Quality
Q8_08 bpw
358.0 GB
VRAM required
100%
Quality
FP1616 bpw
715.5 GB
VRAM required
100%
Quality
Benchmarks (7)
AIME85.3
AA Math85.3
GPQA Diamond71.9
AA Intelligence23.4
AA Coding19.7
LiveCodeBench16.0
HLE8.9
GPUs that can run this model
At Q4_K_M quantization. Sorted by minimum VRAM.
Find the best GPU for GLM 4.6
Build Hardware for GLM 4.6